Using Deep Learning to solve CAPTCHAs

Introduction
CAPTCHA stands“ for "Completely Automated Public Turing test to tell Computers and Humans Apart". They were designed to prevent computers from automatically filling out forms by verifying that you are a real person. With the rise of deep learning and computer vision, machines can now solve CAPTCHAs easily. In 2014, a Google analysis found that artificial intelligence could crack even the most complex CAPTCHA and reCAPTCHA images, rendering the programs useless as security devices. In their place, Google unveiled the now-familiar “No CAPTCHA reCAPTCHA” system but most websites still use CAPTCHAs.
In this post, we’ll be looking at how we can use a deep learning model to solve CAPTCHAs.
Deep Learning Approach
The recent surge of interest in deep learning is due to the performance. It is found that the performance of the model increases with increase in the size of training dataset unlike the traditional machine learning algorithms whose performance becomes constant after a point. Convolutional Neural Networks (CNN) are the most popular deep learning architecture. It is the go-to-model for every image related problem.
A classic CNN would be like this:
Input-->Conv-->RELU-->Pool-->Conv-->RELU-->Pool-->FullyConnected-->Output
As you can see, there are four important operations - Convolution, RELU, Pooling (Sub-Sampling), and Fully Connected. Before looking at each of them in detail, let us first understand how image is represented in a computer.
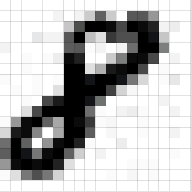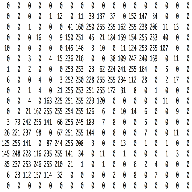
Each image (from a standard camera) has three channels - red, green, blue. Each channel has matrix of pixel values ranging from 0 - 255. These three are stacked upon one another. So an image of size 20x20 is represented as an array of size 20x20x3. When converted to grayscale, the image will have only one channel.
Now, the Convolution
Convolution layer is a feature identifier. Imagine it as a flash light that is shining on the image and moving, starting from top left. The area the flash light is covering is called filter( or kernel). Filter is a matrix of numbers depending on the feature to be identified. Starting from the top left part of the image, the filter does element wise multiplication with the values in the image in its area and sums up the values. Now the filter slides by let’s say 1 unit ( called stride) and repeats the same process. This continues until it reaches the bottom right of the image. The matrix of values formed by this process is called ‘Activation Map’ or ‘Feature Map’ or 'Convolved Feature'

To put this in simple terms, let’s say our filter identifies lines. Then the resulting feature map will consist of higher values in the area where there is a line due to element-wise multiplication and 0 where there are no lines.
RELU
RELU stands for Rectified Linear Unit. It is a non-linear operation done after every Convolution layer. RELU replaces all negative pixel values in the feature map by zero. The purpose of ReLU is to introduce non-linearity in our Convolution Net.
Pooling a.k.a Sub-sampling
Pooling reduces the dimensionality of each feature map while retaining the most important information. It is of different types - Max, Average, Sum. Max Pooling is most widely used.
In Max Pooling, we define a spatial area, let’s say 3x3 and take the largest element from the rectified feature map within that area. We then slide it by a unit like we did for convolution and repeat the process. This layer helps in controlling overfitting as the number of parameters and computations in the network are reduced.
Fully Connected
Fully Connected layer is a multi layer perceptron that uses softmax function (any other classification function can also be used) in the output layer for classification. The high level details of the image obtained from Pooling are used to output an N dimensional vector (N being the no.of classes in the data) representing probability of each class.
Generating CAPTCHAs
To train any machine learning system, we need data. For our problem, we need atleast 10000 CAPTCHAs. I have used the Python library, Claptcha and modified its function to suit my needs. Using a simple for loop, I generated 10000 CAPTCHA images with the captcha text as file name.

You can dowload the script here
Dataset Creation
Now that we have the images, we can train the model. Wait! Wouldn’t it be simpler to teach 26 alphabets than teach 10000 texts directly? Yes, it is!
We will split the CAPTCHA image into individual letters and train the system to identify individual letter and then join them into one string. OpenCV has a function findContours to identify boundaries around continuous regions. Using this function, image can be split into individual letters. I have written a python script to extract letters and group all letters into folders. The images are grouped into folders like this after running the script.

Processing done in this step:
- Images are inverted to have black background and white text.
- The bounding rectangle of the contour is increased by 5 units to acocunt for the space between Q and its tail.
- For some images, two characters were detected to be in one contour. This was accounted for by splitting the bounding rectangle into two if the width of contour > 65.
You can download the script here
Training the model
I have used the following CNN architecture through keras library in Python to train the model
Input-->Conv-->RELU-->Pooling-->Conv-->RELU-->Pooling-->FullyConnected-->Fully Connected-->Output
How does training happen? Well, first all filters and weights are initialized with random values. The network takes an image as input and gives an output.This is forward propagation. Since weights are random, output is also random. Now, error at the output layer is calculated. Now using back propagation, gradients of error are calculated and weights are updated to minimize the error. The same process is repeated for all the images in the dataset.
After 10 epochs, my model has given a validation accuracy of 98.99%!!

Check out keras blog for tutorials on building the model. It can be achieved in few lines of code!
Testing
For testing, I have generated 2000 more CAPTCHAs. I have saved the model as hdf5 file and tested the images. The accuracy was around 98% !
Try it out!
I have created a simple application using Tkinter to demonstrate the capabilities of the model. The application has two buttons - 'Generate' and 'Predict'. Generate is used to generate a CAPTCHA. Predict is used to predict the text, which will be displayed under the CAPTCHA.
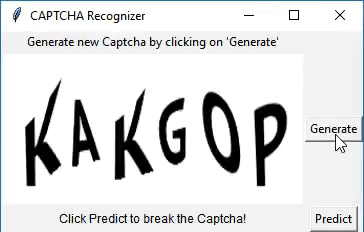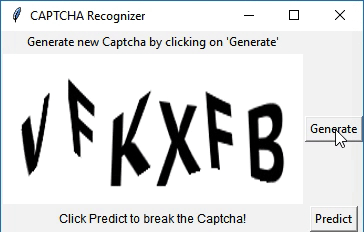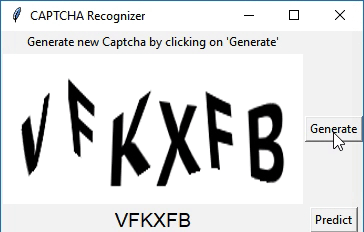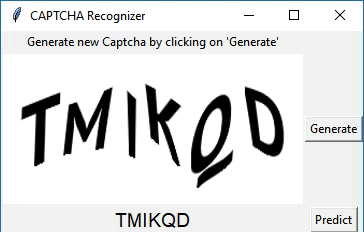
Wanna try it out? Download the python script for the app here